What is it?
Used for Deep Learning, as an activation function of an Artificial Neural Network, the ReLU function, which stands for Rectified Linear Unit function, is probably the most used activation function in Deep Learning. The ReLU function is also non-linear and very fast to compute, once it output the input directly if it’s positive, otherwise, if the input is negative or zero, outputs zero.
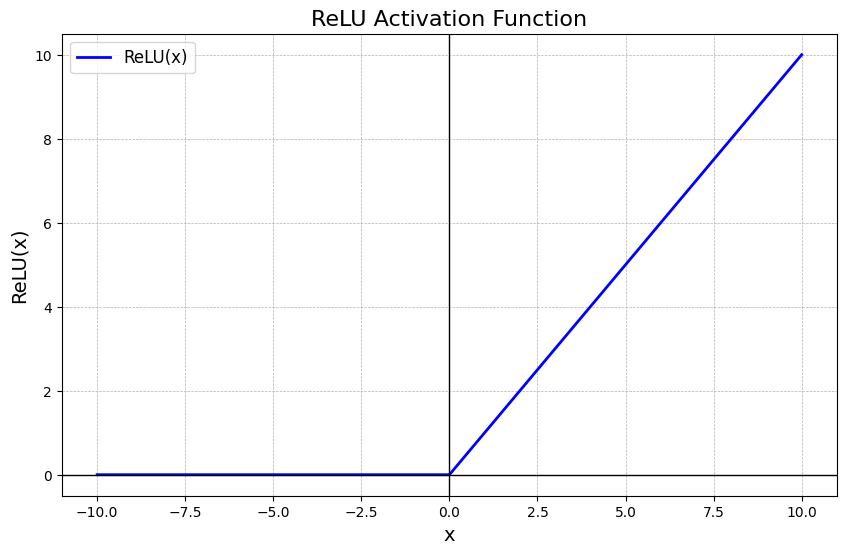
It can be mathematically defined as:
Which return the maximum value between 0, or . One could also rewrite as:
x,\ \ \ x > 0 \\ 0, \ \ \ x \leq 0 \end{cases}However, it’s possible that some neurons become inactive during training, without ever recovering. These neurons always output zero and stops contributing to the learning process. This issue is known as dying ReLU. The derivative of the ReLU function is either or , and on the cases of negative inputs, the gradient becomes zero.
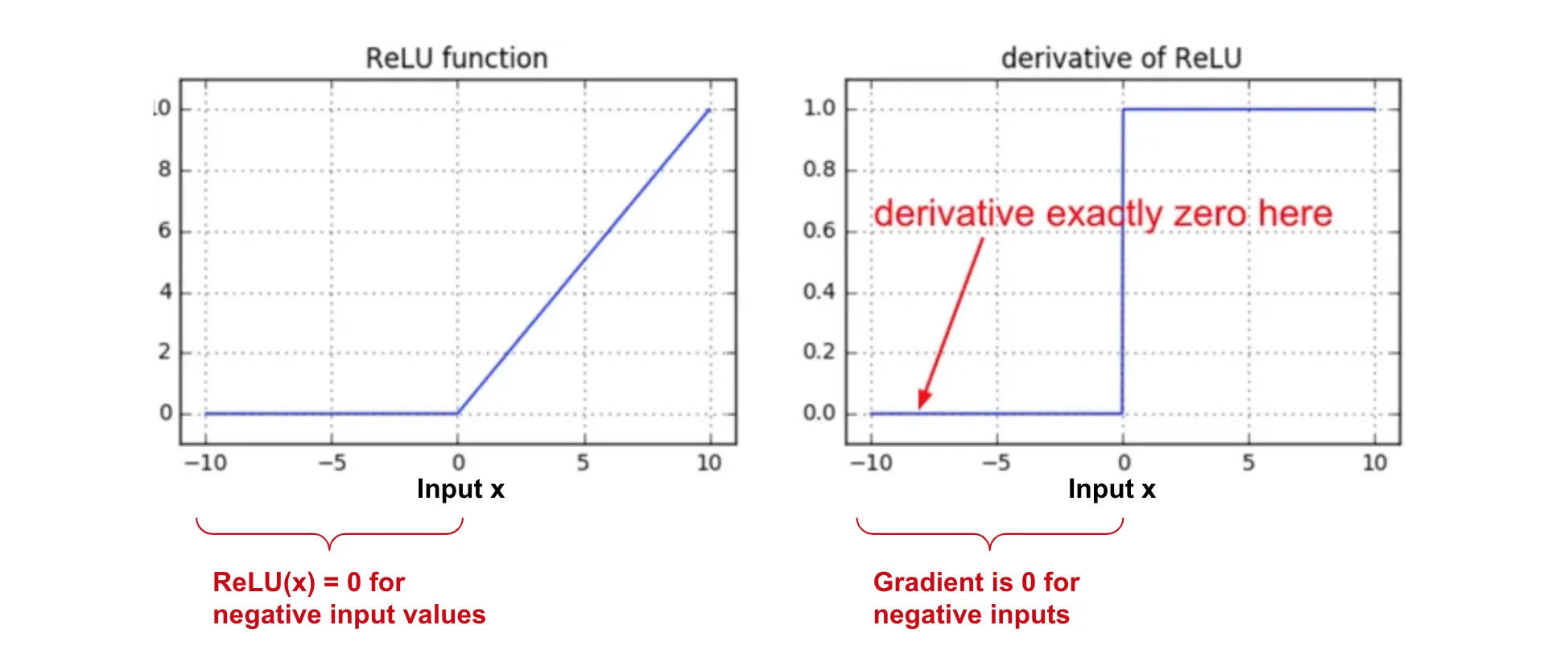
In these cases, the Leaky ReLU Function can be used to mitigate the dying ReLU problem.