What is it?
In Machine Learning, the silhouette score is a metric used for Clustering algorithms using the mean silhouette coefficient of all data samples, which does not need labeled data.
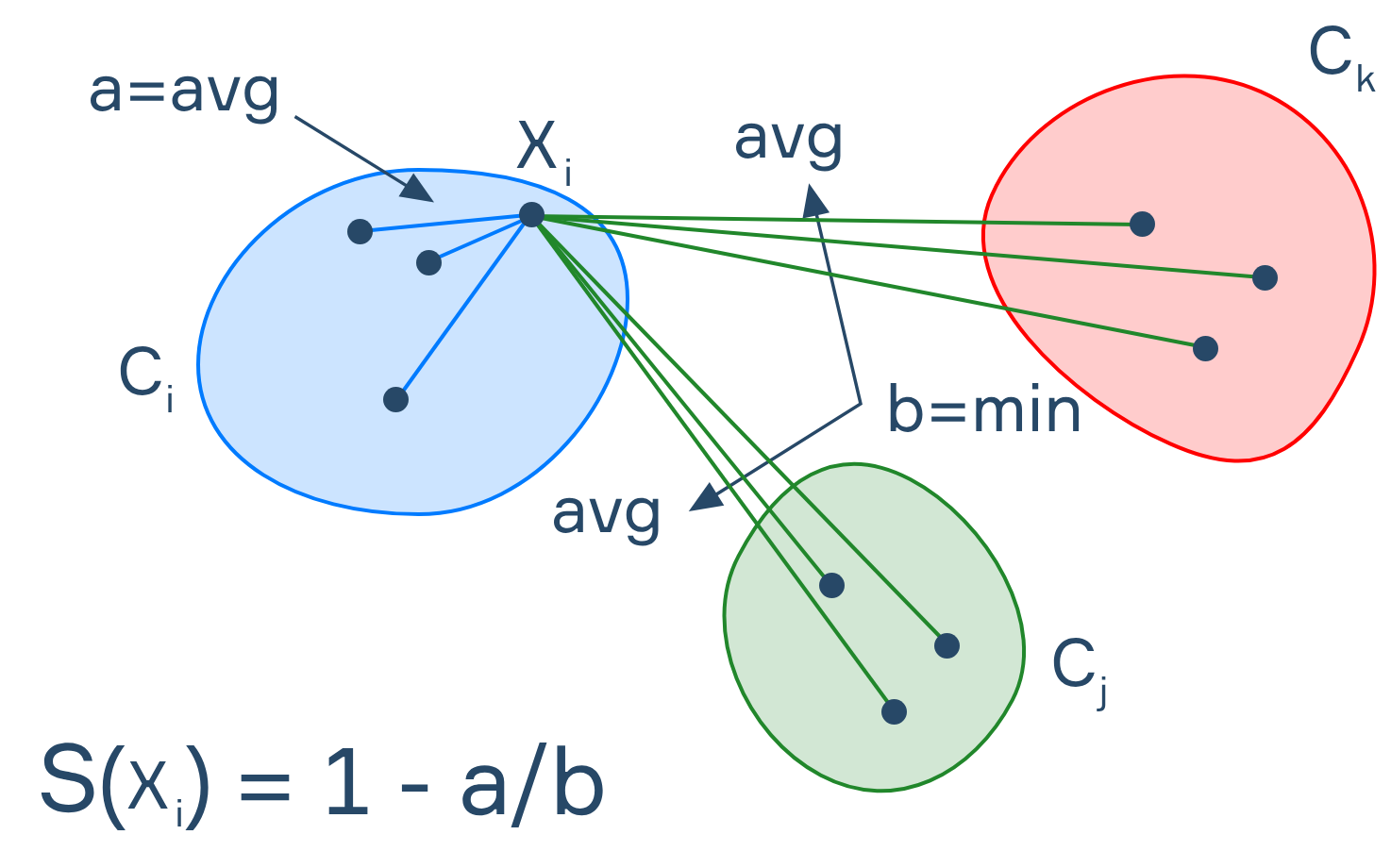
The silhouette coefficient measures how well each data point fits into its cluster. It matches both cohesion (how close a data point is to other points of its own cluster), and separation (how far a data point is from points in other cluster).
Why silhouette score?
Most metrics for clustering algorithms need labeled data, which for clustering problems, the dataset will not contain any label for the data. Instead, silhouette score demands only features data and the predicted clusters. This differs from other metrics used for clustering algorithms, which needs true labels for evaluation.
The shortcoming of silhouette score
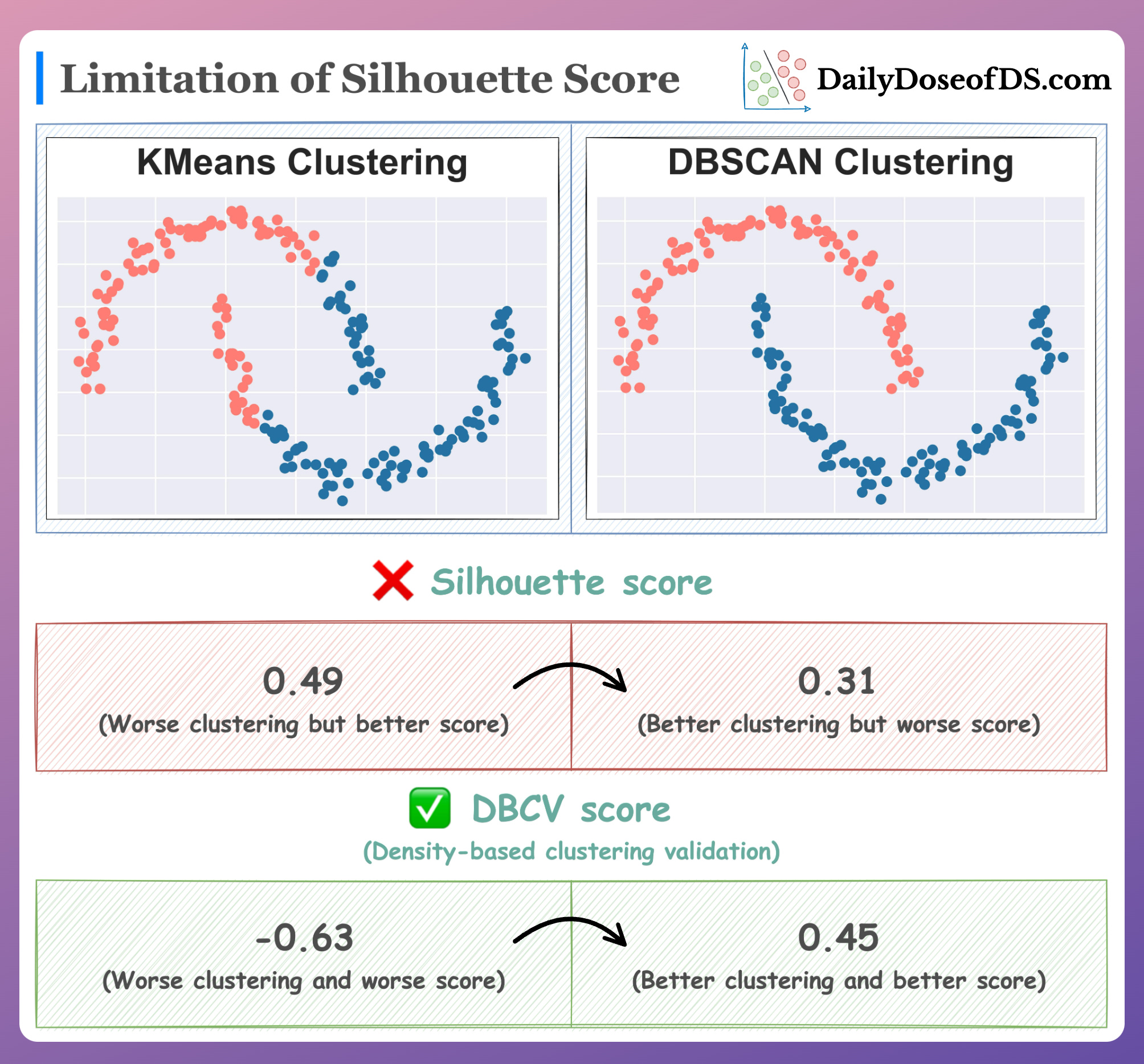
Silhouette score can present inaccurate scores for clusters which are not spherical shaped. It only considers the mean distance of a single sample, while not taking into account information about other samples. This leads to clusters with abstract shapes that can have better clustering, but worse scores.
Calculation
For a specific data point, its silhouette coefficient is calculated as:
Where is cohesion, the mean distance between and all points in its own cluster, and is separation, the smallest mean distance of to all points in other clusters, which can be calculated for each data point as:
Where is the number of data points belonging to the cluster , is the distance between data points and .