What is it?i
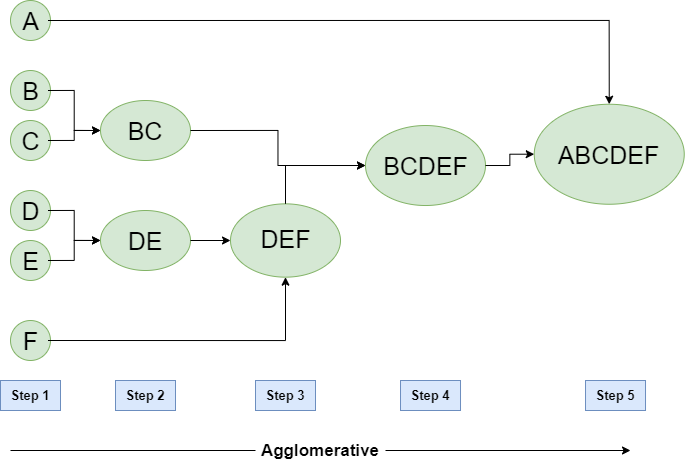
In Machine Learning, agglomerative clustering is a Unsupervised Learning algorithm for hierarchical-based clustering, meaning that it builds a tree from the leaves, with each being a single data point, and then clusters these leaves until it reaches a single cluster, that is the root of the tree.
How does it work?
The algorithm supposes that all data points are clusters, and then, tries to merge them together until the desired number of clusters is reached. Each step merges the two nearest cluster to each other. However, various method can be used to determine the nearness of two clusters.
Metrics of nearness
Some metrics used to determine nearness, and available in scikit-learn are: Euclidean Distance, Manhattan Distance, cosine distance and a pre computed metric.
Linkage criterion\
To determine which clusters should be merged, scikit-learn uses the linkage criterion, which are methods that decide what’s the criteria used to minimize the selected distance metric, which can be:
-
Single
Uses the minimum of the distances between all points in two clusters, merging clusters with the the minimum value of the single criterion.
-
Complete
Uses the maximum distance between all points in two cluster, merging clusters with the the **minimum value of these maximum distances.
-
Average
Uses the average distance between points in clusters, merging clusters with the minimum value of averages.
-
Ward
Minimizes the Variance of points in two clusters, merging clusters which will have the maximum impact on minimizing the Variance.