What is it?
K-Means is a Machine Learning algorithm used in Unsupervised Learning and centroid-based Clustering tasks. It can be easily implemented with scikit-learn.
How does it work?
The K-Means algorithm need the number of centroids before initiating the learning phase, meaning that it should be decided by the data scientist, either directly or using another algorithm to optimally retrieve a possible best number of centroids.
What are centroids?
A centroid is coordinate where the cluster will be centered upon, meaning that all data points will be calculated in reference to the centroid. It’s also considered the mean of the cluster, once that K-Means place the output centroids as the average of the distance between all instances from the cluster
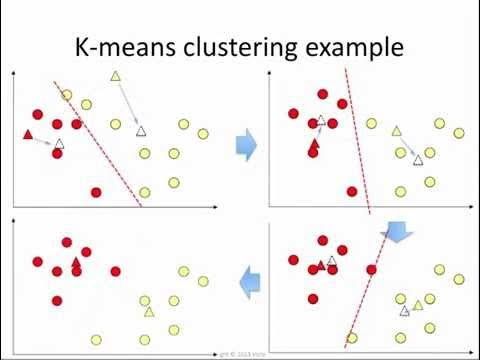
The algorithm
It’s also possible to preemptively determine the initial position of the centroids, or to randomly let the algorithm decide.
Each data point is assigned to each cluster considering the nearest centroid, and the centroid is recalculated. Then, if no centroid moved, then the algorithm has reached convergence, and the clusters are formed.
Pseudo algorithm
Select and initialise K centroids
Repeat:
For each data point:
Assign to the nearest cluster
For each centroid:
Update coordinates, depending on the mean distance
Have centroids converged?
Yes: stop iterating
No: keep going