What is it?
Hash tables are a data structure in which the address of the data is generated from Hash Functions, which enables much faster data access than needing to apply a search algorithm. A hash table works with key-value pairs, with the key being a shortcut to the index of the desired value. The index can be calculated to insert, remove and retrieve the desired value.
Implementations of hash tables
Hash tables are widely implemented in various programming languages, like the dict structure in Python and the HashMap structure in Java.
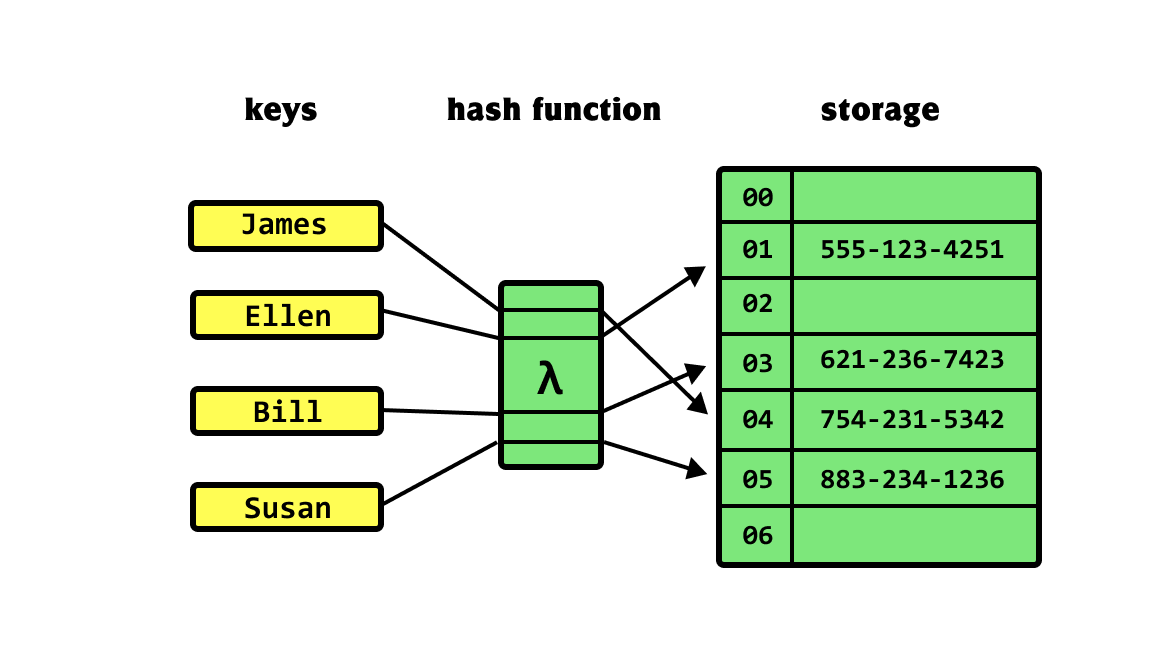
How does it work?
Given a key-value pair, like the name of a product and its price, one can implement a hash table structure which will store this data. When doing any operation, the key will go through a hash function, which will then result in the index which will be inserted in a array.
public class SimpleHashTable
{
private object?[] Values;
protected int Length;
public SimpleHashTable(int length)
{
Length = length;
Values = new object[Length];
}
internal bool IsKeyTypeValid(object key)
{
return key is string or int;
}
internal int HashFunction(int number)
{
return number % Length;
}
internal int HashFunction(string word)
{
char[] characters = word.ToCharArray();
int sum = 0;
// Sums all ASCII numbers of each character.
for (int i = 0; i < characters.Length; i++)
{
int asciiNumberOfChar = (int)characters[i];
sum += asciiNumberOfChar;
}
return HashFunction(sum);
}
public void Insert(int key, object value)
{
int index = HashFunction(key);
Values[index] = value;
}
public void Insert(string key, object value)
{
int index = HashFunction(key);
Values[index] = value;
}
internal virtual bool IsIndexEmpty(int index)
{
return Values[index] is null;
}
public void RemoveFromKey(string key)
{
int index = HashFunction(key);
RemoveAt(index);
}
public void RemoveFromKey(int key)
{
int index = HashFunction(key);
RemoveAt(index);
}
public void RemoveAt(int index)
{
// Index out of bounds are treated by Array class.
if (!IsIndexEmpty(index))
Values[index] = null;
}
public virtual object Get(string key)
{
int index = HashFunction(key);
return GetAt(index);
}
public virtual object Get(int key)
{
int index = HashFunction(key);
return GetAt(index);
}
internal virtual object GetAt(int index, object? defaultReturn = null)
{
if (!IsIndexEmpty(index))
return Values[index];
return defaultReturn;
}
}Working with collisions
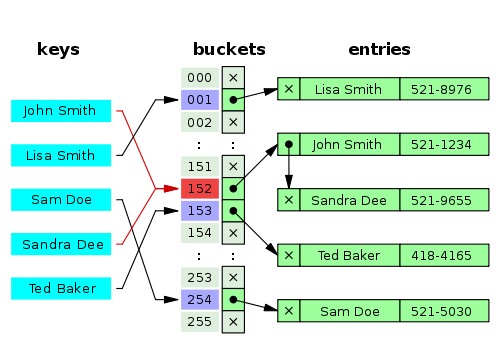
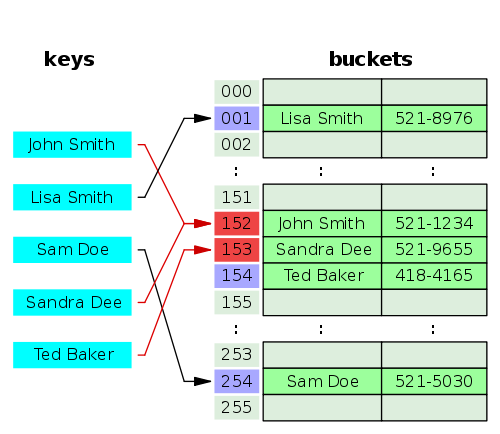
Even for different key values, a hash function may result in the same index. If two or more values with the same index occurs, a collision happens.
Implementing the key into the store value
To work with collisions in hash tables, one must certify that the index actually corresponds with the desired key, and not another one that collided. To do this, storing key-value pairs instead of only the value and then checking for each iteration is the most efficient way.
There are two main ways to mitigate collisions, with probing for open addressed tables, or with separate chaining.
Probing
In this case, the hash table will only let a single data value be stored on the same index, characterizing a open addressing table. Then the data which collided shall “look for another place to be inserted”.
This can be done linearly with the index being recursively incremented until it finds a empty space to be inserted.
Separate chaining
This case characterizes a closed addressing table, which permits multiple values being stored in the same index, as long as it implements “multi-index solution”, like storing Linked Lists, which then will store multiple key-value pairs.