What is it?
MapReduce is a programming model which enables fast Distributed Computing of large datasets, mainly used for Big Data applications in Data Engineering.
Originally published in 2004 by Google’s engineers, the MapReduce paper is still widely used in cloud, spawning AWS Elastic MapReduce, which is basically a MapReduce module for managing data processing. Probably it’s most famous implementation is in the Big Data framework, Hadoop.
How does it work?
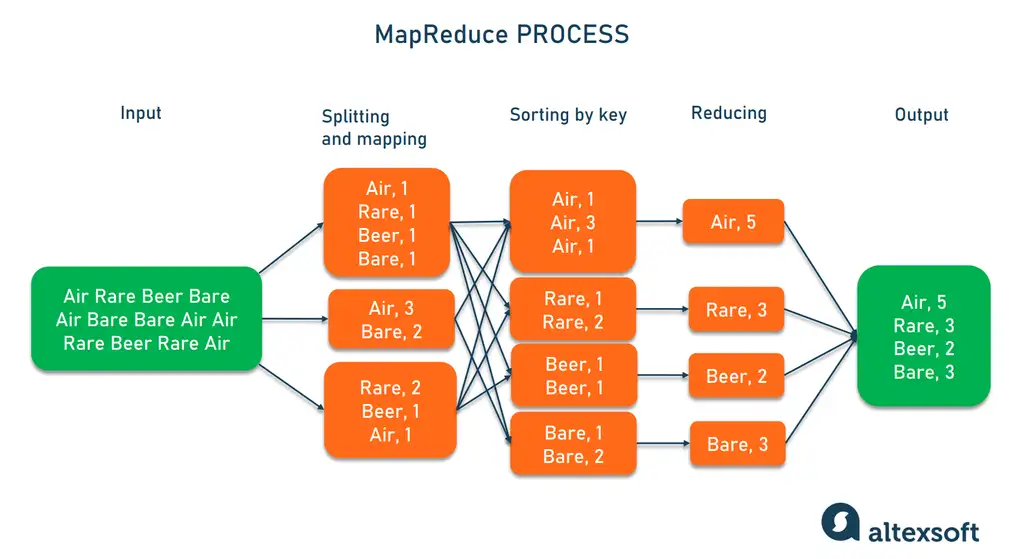
The MapReduce has three steps: mapping, sorting and shuffling, and reducing.
-
Map
The mapping function splits large data inputs into smaller chunks, applying pre-defined rules to convert into key-value pairs. A simple mapping function could be the count of each word in a text input, for example.
-
Sort and shuffle
Sorting and shuffling the resulting key-value pairs, enables the algorithm to aggregate similar key-values which were processed on different machines.
-
Reduce
The reduce function processes the sorted key-values into the final desired output. It could be a sum of each key-value pair, for example.