What is it?
In the book Big Data - Principles and Best Practices, Nathan Marz and James Warren proposed a new architecture pattern for Big Data systems which accomplish both batch processing and stream processing, with one or more pipelines.
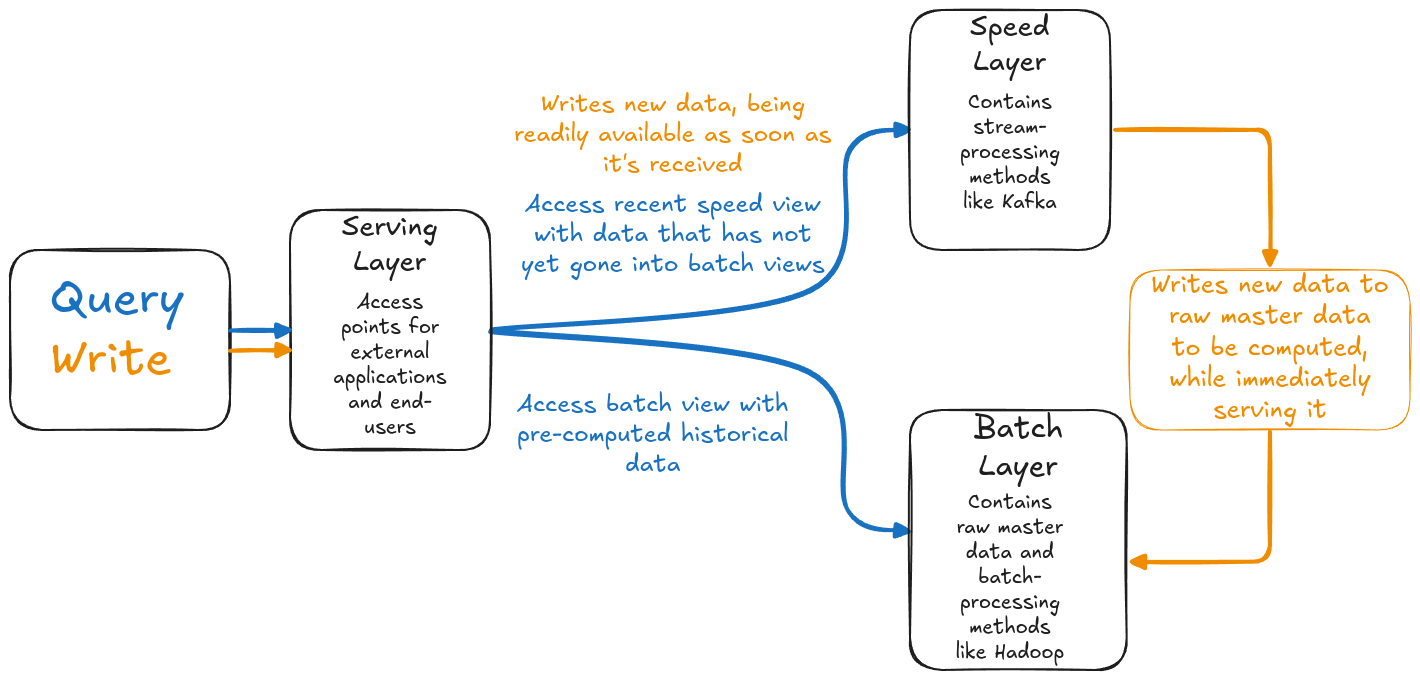
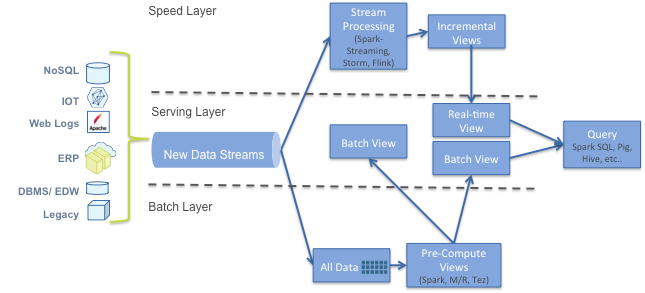
This is the lambda architecture. It proposes that a Big Data system should be build upon three layers, each responsible for a different facet of the system.
The layers of lambda
The lambda architecture is separated by three main layers: the batch, speed and serving layers.
-
Batch layer
Stores the raw master data in distributed storage like HDFS or AWS’ S3. Pre-compute views for faster consulting on a scheduled basis, defining its latency based on the schedule of its batch processing.
-
Speed layer
Designed to handle real-time data processing, with low-latency views of the data, using stream processing to achieve this.
-
Serving layer
Merges the result of both the batch and speed layers, providing an unified view of the data. This is where end-users, applications and queries have access to the system. By merging both layers, the serving layer achieves real-time, consistent, and low-latency queries to the data.
How a query would work?