What is it?
For a given Machine Learning model, it’s possible for the loss of a specific subpopulation of the data to be significantly higher than the rest of the dataset. For example, Generative AI is known to have issues in human-centric data, like race, gender and socio-economical factors, i.e., some races may perform better in facial recognition than others.
A model prediction should not depend on which subpopulation a data point belongs to, and needs to be able to generalize proportionally well across the entire distribution.
This is different from Class Imbalance, where it focuses on the target variable. Here the focus is on the features itself.
Discovering underperforming samples
It may not be easy to identify the characteristics of the underperforming subpopulation, so one should be able to strategize ways to find these subgroups where the model underperform, most commonly, using Data-Centric Evaluation methods.
A common strategy is error analysis and clustering, i.e., Slice Discovery
Error Analysis
Evaluate your model using validation data, and sort the examples by loss value, which would be the ones where the model is performing poorly. Then try to identify any patterns, mislabels or noisy data.
Error Clustering
Apply clustering techniques only to the examples identified by the step above, and figure out subgroups and patterns among the examples.
Clustering can be done by applying a single distance metric between two examples, using unsupervised learning. Plotting and inspecting the resulting clusters can expose patterns the model struggles to capture.
It’s also possible to make this method be label-aware, instead of unsupervised. Which is done by using SDMs.
Slice Discovery Methods — SDMs
Slice Discovery is the task of mining input data for meaningful subpopulations on which the model performs poorly. Any automated technique that performs this task can be called a Slice Discovery Method.
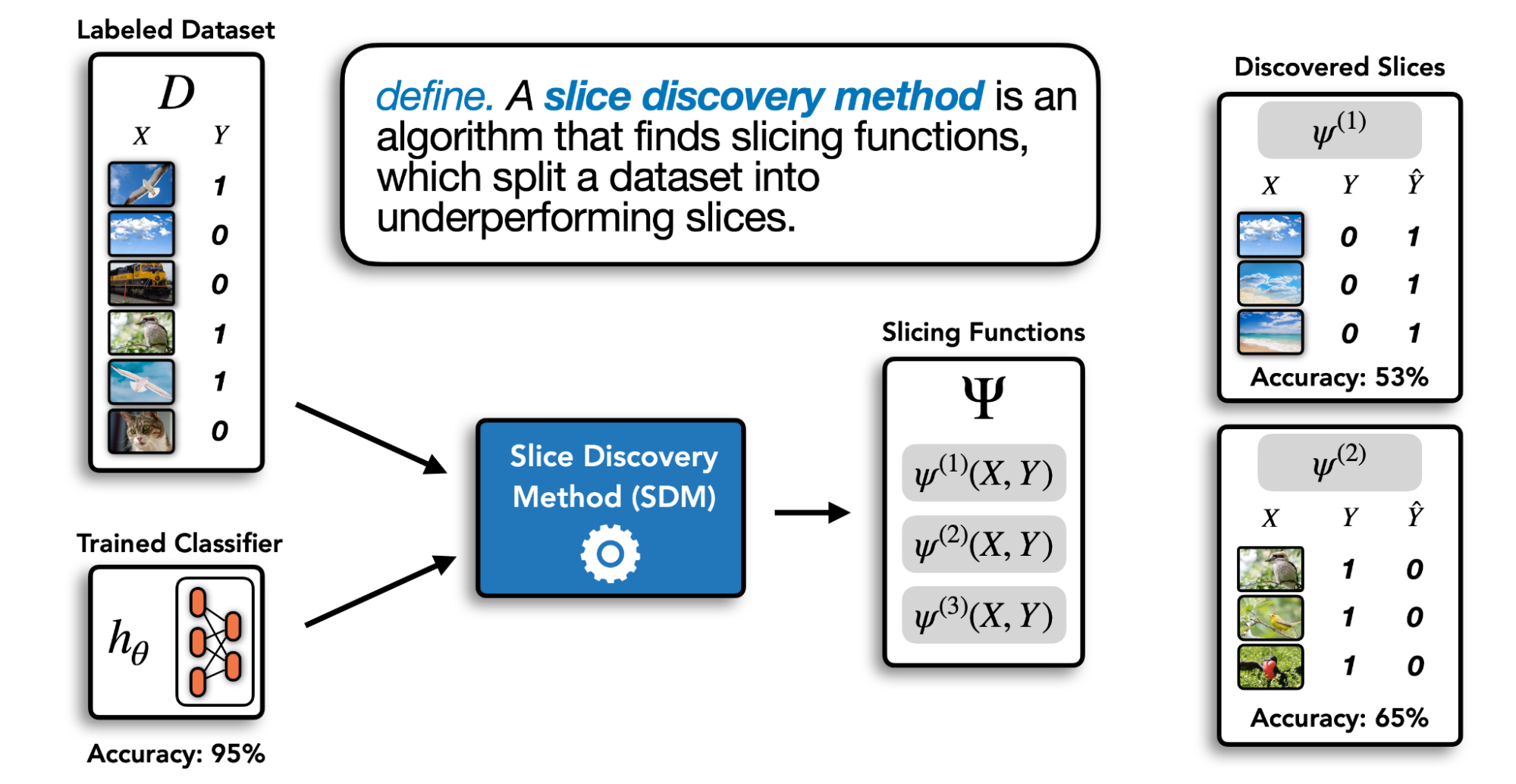
A recent SDM using cross-modal embeddings is Domino.
Improving model performance
Here are some ways to improve model performance for a specific sample:
-
Trying a more flexible model;
-
Over-sample or up-weight the subpopulation;
-
Collect additional data;
-
Measure or engineer extra features for the specific sample.
-
Use Fairness Metrics for evaluation.