What is it?
The Term-frequency representation, also referred to as TF, for short, is a way of representing sentences in Vectors, counting each word and adding to its index in the vector. It’s different from the One-Hot vectorization, where an index can go up to an infinite sum of its present words.
It’s widely used in Natural Language Processing and Large Language Models for Deep Learning purposes.
How does it work?
For a given sentence time flies like fruit flies, one can assume an one-dimensional vector with length equal to the sum of distinct words in the sentence.
For our example, this would yield in a vector with length of . We could also represent our vector like this:
Now, we count the presence of each word and assign its sum to its corresponding index. Because the word flies appear twice, we have a single index for it and assign the count of , resulting in:
Applying to a dataset
When applying TF methods to an entire dataset, one would first create a vector with all possible words. This results in sentences with a lot of on it. Another common practice is to transform all words to lower and remove punctuation before applying a vectorization method.
The most frequent words will have higher weights applied to them, meaning that they are more important to the model. However, very common words may not actually be significant, and rare words are.
In these cases, one may prefer to use Inverse-Document-Frequency.
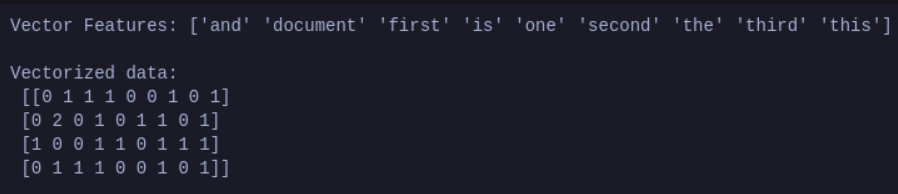
Applying in Python
One can easily apply a Term-frequency method in Python, using scikit-learn as the Machine Learning framework:
from sklearn.feature_extraction.text import CountVectorizer
data = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(data)
print(f"Vector Features: {vectorizer.get_feature_names_out()} \n")
print(f"Vectorized data: \n {X.toarray()}")